
|
StuBS
|
This introduction's goal is to give youe a concise overview to assembler programming. It is aimed at students of the lecture 'Operating Systems' that do not have any experience in assembly programming yet.
At the end of this introduction you will not be able to write complex programmes using assembly, but you will not have to do something like that during the lecture's exercises anyway. We hope, however, that you learn how programmes written in a high level language such as C look like, after having been transformed to assembly. Additionally, you should be able to write simple functions in assembly after finishing this introduction.
All concepts explained below will contain examples based on the x64 processor family, which is the (downwards compatible) successor to the x86 architecture. These processors were originally developed by Intel and are part of basically every modern PC. The assembly syntax used here is the one used by the Netwide Assembler (NASM). It is the same one you will be using during development of your operating system OOStuBS or MPStuBS.
An assembler basically is just another compiler that translates code of a programme written in assembly into machine code, that is, zeros and ones. The main difference between an assembler and a compiler for higher level languages, like C for example, is the fact that most of the time each assembly instruction corresponds to exactly one instruction of the respective processor's machine code. You can think of the assembly being a human-readable version of machine code.
So instead of writing
000001011110100000000011
you can use the assembly instruction
add ax,1000
. On x64 processors, both encode the same instruction.
| Symbolic Name | Machine Code |
|---|---|
| add ax | 00000101 |
| 1000 (decimal) | 0000001111101000 |
Addionally, the assembler exchanges the offset's bytes order.
| add ax | low-Byte | high-Byte |
|---|---|---|
| 00000101 | 11101000 | 00000011 |
Most of the time when we talk about "the Assembler" we actually do not talk about the compiler itself, but its respective symbolic notation for instructions. So add eax,1000 is an assembler instruction.
An assembler can actually do very little, namely only what the respective processor directly understands. Especially most of the language constructs used in higher level languages in order to express algorithms in an understandable manner are missing. This includes:
for, while and repeat-until loops (assembly almost exclusively uses gotos)Here are some examples:
The C Statement
sum = a + b + c + d;
is too complicated for a single assembly instruction and is, therefore, split into several instructions. x64 processors can only add two values at the same time, the result is then stored in one of the two "variables". The following C programme is closer to a programme written in assembly:
sum = a; sum = sum + b; sum = sum + c; sum = sum + d;
One possible translation to x64 assembler would look like this:
mov rax,[a] add rax,[b] add rax,[c] add rax,[d] mov [sum], rax
if-then-else statements are also too complex for an assembler: if (a == 4711) {
...
} else {
...
}
and, therefore, have to be expressed by using gotos: if (a != 4711)
goto not_equal
equal: ...
goto out:
not_equal: ...
out: ...
This is how you would express that using x64 assembly: cmp rax,4711
jne not_equal
equal: ...
jmp out
not_equal: ...
out: ...
for-loops, however, x64-based processors have better support. The following C programme for (i=0; i<100; i++) {
sum = sum + a;
}
looks like this in x64 assembly: mov rcx,100
forloop: add rax,[a]
loop forloop
The loop instruction implicitly decrements the value stored in rcx (rcx is the **c**counter register). It does only jump back to the label forloop, if the value stored in ecx is not equal to zero after decrementing it.The assembler examples above used register names rather then the variable names used in the C examples. A register is a tiny piece of hardware located on the processor used to store values. On x64-based processors, each register may store values of up to 64 bits in size.
Processors of the x64 family have the following registers. They can be divided into sub categories based on their purpose.
| Name | Bemerkung |
|---|---|
| Allgemein verwendbare Register | |
rax | general purpose, has special meaning for some arithmetic instructions |
rbx | general purpose |
rcx | generap purpose, has special meaning for loops |
rdx | general purpose |
rbp | base pointer |
rsi | general purpose, source register for string operations |
rdi | general purpose, destination register for string operations |
rsp | stack pointer |
r8 | general purpose |
r9 | general purpose |
r10 | general purpose |
r11 | general purpose |
r12 | general purpose |
r13 | general purpose |
r14 | general purpose |
r15 | general purpose |
| Segment registers | |
cs | code segment |
ds | data segment |
ss | stack segment |
es | arbitrary segment |
fs | arbitrary segment |
gs | arbitrary segment |
| Spezialregister | |
rip | instruction pointer |
rflags | flags register |
As we have already pointed out, the x64 processor is downwards compatible to its predecessor, the x86 processor. Furthermore, it is also downwards compatible to the x86's predecessors. Therefore, it is possible to access subsets of the bits stored in the registers rax, rbx, rcx and rdx by using special register names. The following graphic illustrates this for the register rax.

Most of the time the limited amount of registers is not enough to solve more complex problems. In that case we have to access the computer's main memory, which can hold much more information than the processor's registers. From an assembly programmer's point of view, the main memory looks like an incredibly large array of registers. Where each of these "registers" may have a size of 8, 16, 32 or 64 bits. The smallest addressable unit is one byte (i.e. 8 bits). Therefore, the memory's size is usually measured in bytes. In order to address a certain entry in main memory, the programmer has to know the index, that is, the address of that entry. The memory's first byte has address 0, the second address 1 and so forth.
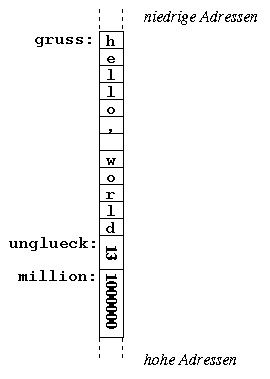
We can create variables in assembly programmes by assigning a label to a memory location and allocating the desired amount of space:
[SECTION .data]
greeting: db 'hello, world'
badluck: dw 13
million: dd 1000000
[SECTION .text]
mov ax,[million]
...
|  |
If we temporarily need to store a register's value in main memory, we do not always want to come up with a new label for it. Sometimes we might need that specific register for another computation, but will use its current value at a later point in time for example. In that case we would like to have something similar to a scratch pad. That is exactly what a stack is used for. Actually, the stack is just a piece of main memory, but instead of working with addresses we simply push values onto it or remove (pop) the topmost value from it. Accessing it is that simple as long as you remember the order in which you pushed the values. The special register rsp (stack pointer) holds the address of the stack's topmost element on x64 processors. The stack's values in the picture below are shown as being 8 bytes large, since the push and pop instructions may at most transfer 64 bits at once.
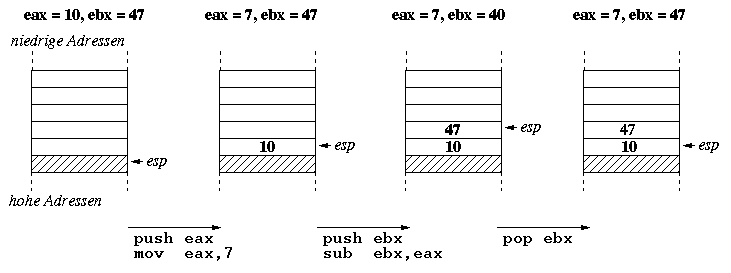
Most of the x64 processor's instructions may read their operands from registers, main memory or immediate (constant) values. The mov instruction, for example, moves a value from its source (the second) operand to its destination (the first) operand. The following combinations are possible:
mov rbx,1000mov rbx,[1000]mov rbx,[rax]mov rax,[10+rsi]You probably are already familiar with the concept of functions or procedures from higher level programming languages. Unlike gotos, functions may be called from arbitrary points of your programme and programme execution is continued at the statement below the function call, once the function returns. Futhermore, the function does not have to know from where it was called or where the execution continues after it has returned. How does this work?
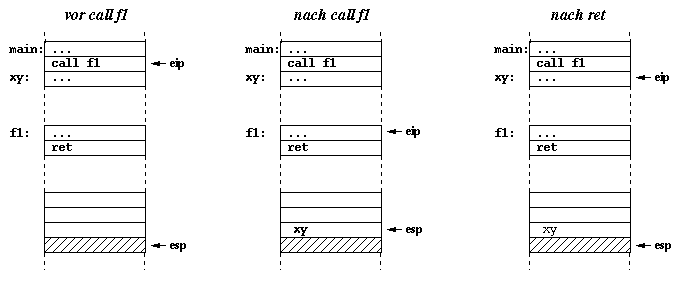
The solution to this problem is that the programme's instructions are stored in main memory during its execution, just like its data is. Therefore, each machine code instruction has an address. In order for the processor to execute a programme, its instruction pointer has to contain the address of the first instruction of that programme. The processor will then load the instruction from main memory, execute it and increment the value of its instruction pointer by the size (in bytes) of the instruction, which yields the address of the next instruction. If the instruction is a jump instruction the instruction pointer is not incremented or decremented based on the insruction's size, but by the relative target address encoded in the instruction.
Function calls work similar to jumps, but the processor has to push the address of the instruction following the function call (i.e. the instruction pointer's current value plus the size of the call instruction) onto the stack, before updating the instruction pointer to point to the function's address. The address stored on top of the stack is called return address. The function may then return to the caller simply by moving the previously stored address from the stack in to the processor's instruction pointer.
On x64-based processors, the call instruction implicitly pushes the return address onto the stack. Its counterpart, the ret instruction implicitly removes the return address from the stack and stores it in the instruction pointer.
; ----- Main Programme -----
;
main: ...
call f1
xy: ...
; ----- Function f1
f1: ...
ret
Depending on the so-called calling convention, a function's arguments may be located in registers or pushed onto the stack or both. On x86 all arguments used to be stored on the stack, while on x64 the first six parameters are typically stored in registers and further parameters are pushed onto the stack.
When passing arguments on the stack, we have to push them before executing the call instruction and remove them from the stack after the function returns. The latter is either done by using the pop instruction or changing the stack pointer's value directly:
push rax ; f1's second parameter
push rbx ; f1's first Parameter
call f1
add esp,16 ; Remove parameters from stack
; (the stack grows from high to
; low addresses).
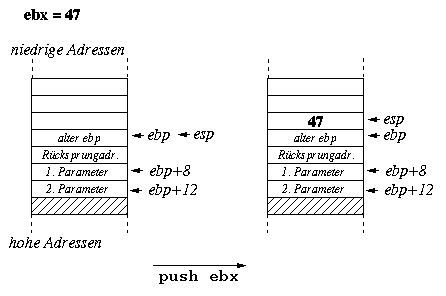
In order to easily access a function's arguments, we can make use of the base pointer rbp. The base pointer points to the beginning of the stack frame of a function call. Usually, the first instruction executed by a function saves the base pointer's current value on top of the stack (push rbp) and then moves the stack pointer's current value into the base pointer register (mov rbp,rsp). This allows us, for example, to always access the first argument stored on the stack via the address [rbp+16] and the second via [rbp+24], regardless of the number of push and pop operations executed during the function call.
f1: push rbp
mov rbp,rsp
...
mov rbx,[rbp+16] ; load first parameter on the stack into rbx
mov rax,[rbp+24] ; load second parameter on the stack into rax
...
pop rbp
ret
It is important to lay down which registers' values a function is allowed to change during its execution and which registers' values it has to preserve, in order for the function to be callable at any given point during the execution of a programme. The safest approach would be to simply push the values of all registers onto the stack at the beginning of the function and restore them before returning to the caller.
However, the GNU-C-Compiler (gcc) uses a different strategy. It assumes that, most of the time, registers are used only briefly, as counter in a loop for example. Therefore, it would be pure waste of resources to save and restore these (proably already outdated) values during every function call. Therefore, the calling convention used by the GNU-C-Compiler specifies that the registers rax, rdi, rsi, rdx, rcx, r8, r9, r10 and r11 are to be treated as volatile registers, that is, their values may be overwritten by a function. The register rax has a special purpose: it contains the result of the function call, if the function returns any value. If a function uses any of the remaining registers not listed above, it must preserve their previous values and restore the value before returning to the caller. Therefore, these registers are called non-volatile.